Next Generation Databases

I wrote this book as an attempt to share what I’ve learned about non-relational databases in the last decade and position these in the context of the relational database landscape that I’ve worked in all my professional life.
The book is divided into two sections: the first section explains the market and technology drivers that lead to the end of complete “one size fits all” relational dominance and describes each of the major new database technologies. These first 7 chapters are:
- Three Database Revolutions
- Google, Big Data, and Hadoop
- Sharding, Amazon, and the Birth of NoSQL
- Document Databases
- Tables are Not Your Friends: Graph Databases
- Column Databases
- The End of Disk? SSD and In-Memory Databases
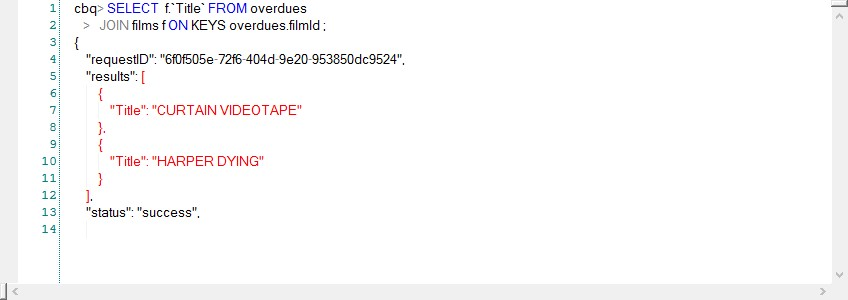
The second half of the book covers the “gory details” of the internals of the major new database technologies. We look at how databases like MongoDB, Cassandra, HBase, Riak and others implement clustering and replication, locking and consistency management, logical and physical storage models and the languages and APIs provided. These chapters are:
- Distributed Database Patterns
- Consistency Models
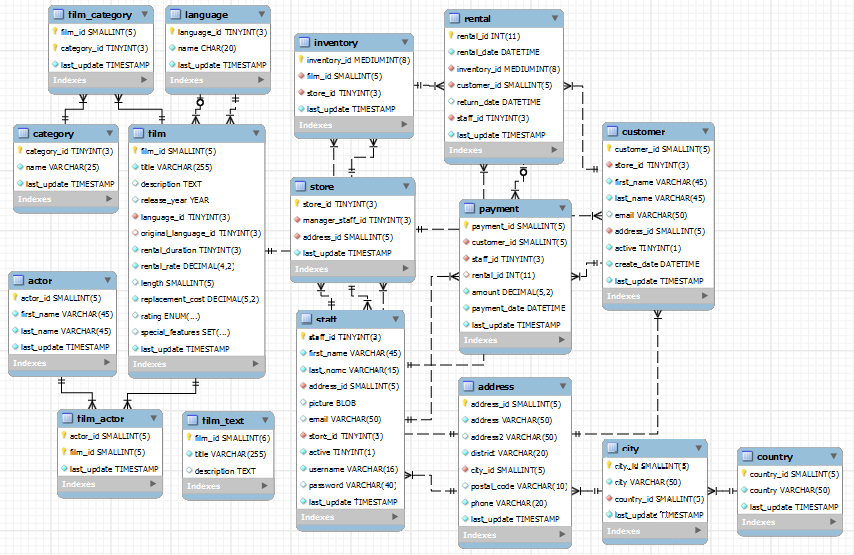
- Data Models and Storage
- Languages and Programming Interfaces
The final chapter speculates on how databases might develop in the future. Spoiler alert: I think the explosion of new database technologies over the last few years is going to be followed by a consolidation phase, but there’s some potentially disruptive technologies on the horizon such as universal memory, blockchain and even quantum computing.
The relational database is a triumph of software engineering and has been the basis for most of my career. But the times they are a changing and speaking personally I’ve really enjoyed learning about these new technologies. I learned a lot more about the internals of the newer database architectures while writing the book and I’m feeling pretty happy with the end result. As always I’m anxious to engage with readers and find out what you guys think!