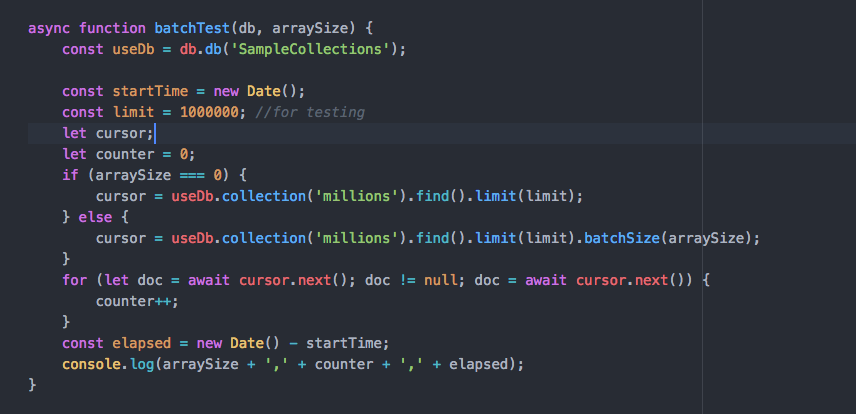
1: while (custRs.next()) { // For each customer
2: String custId = custRs.getString("CUST_ID");
3: String custFirstName = custRs.getString("CUST_FIRST_NAME");
4: String custLastName = custRs.getString("CUST_LAST_NAME");
5:
6: //Create the customer document
7: BasicDBObject custDoc = new BasicDBObject();
8: custDoc.put("_id", custId);
9: custDoc.put("CustomerFirstName", custFirstName);
10: custDoc.put("CustomerLastName", custLastName);
11: // Create the product sales document
12: BasicDBObject customerProducts = new BasicDBObject();
13: custSalesQry.setString(1, custId);
14: ResultSet prodRs = custSalesQry.executeQuery();
15: Integer prodCount = 0;
16: while (prodRs.next()) { //For each product sale
17: String timeId=prodRs.getString("TIME_ID");
18: Integer prodId = prodRs.getInt("PROD_ID");
19: String prodName = prodRs.getString("PROD_NAME");
20: Float Amount = prodRs.getFloat("AMOUNT_SOLD");
21: Float Quantity = prodRs.getFloat("QUANTITY_SOLD");
22: // Create the line item document
23: BasicDBObject productItem = new BasicDBObject();
24: productItem.put("prodId", prodId);
25: productItem.put("prodName", prodName);
26: productItem.put("Amount", Amount);
27: productItem.put("Quantity", Quantity);
28: // Put the line item in the salesforcustomer document
29: customerProducts.put(timeId, productItem);
30: if (prodCount++ > 4) { // Just 5 for this demo
31: prodCount = 0;
32: break;
33: }
34: }
35: // put the salesforcustomer document in the customer document
36: custDoc.put("SalesForCustomer", customerProducts);
37:
38: System.out.println(custDoc);
39: custColl.insert(custDoc); //insert the customer
40: custCount++;
41:
42: }