Sakila sample schema in MongoDB
2018 Update: You can download this and other sample schemas we use in dbKoda from https://medium.com/dbkoda/mongodb-sample-collections-52d6a7745908.
I wanted to do some experimenting with MongoDB, but I wasn’t really happy with any of the sample data I could find in the web. So I decided that I would translate the MySQL “Sakila” schema into MongoDB collections as part of the learning process.
For those that don’t know, Sakila is a MySQL sample schema that was published about 8 years ago. It’s based on a DVD rental system. OK, not the most modern data ever, but DVDs are still a thing aren’t they??
You can get the MongoDB version of Sakilia here. To load, use unpack using tar zxvf sakilia.tgz then use mongoimport to load the resulting JSON documents. On windows you should be able to double click on the file to get to the JSON.
The Sakila database schema is shown below. There are 16 tables representing a fairly easy to understand inventory of films, staff, customers and stores.
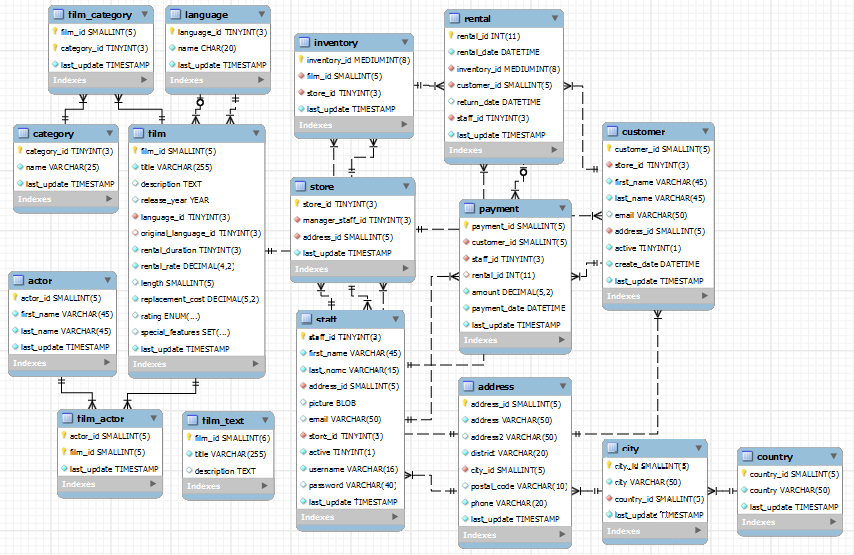
When modelling MongoDB schemas, we partially ignore our relational modelling experience – “normalization” is not the desired end state. Instead of driving our decision on the nature of the data, we drive it on the nature of operations. The biggest decision is which “entities” get embedded within documents, and which get linked. I’m not the best person to articulate these principles – the O’Reilly book “MongoDB Applied Design Patterns” does a pretty good job and this presentation is also useful.
My first shot at mapping the data – which may prove to be flawed as I play with MongoDB queries – collapsed the 16 tables into just 3 documents: FILMS, STORES and CUSTOMERS. ACTORS became a nested document in FILMS, STAFF and INVENTORY were nested into STORES, while RENTALS and PAYMENTS nested into CUSTOMERS. Whether these nestings turn out to be good design decisions will depend somewhat on the application. Some operations are going to be awkward while others will be expedited.
Here’s a look at the FILMS collection:

Here is STORES:

And here is CUSTOMERS:

Looks like I have to fix some float rounding issues on customers.rentals.payments.amount .
The code that generates the schema is here. It’s pretty slow, mainly because of the very high number of lookups on rentals and payments. It would be better to bulk collect everything and scan through it but it would make the code pretty ugly. If this were Oracle I’m pretty sure I could make it run faster but with MySQL SQL tuning is much harder.
Code is pretty straight forward. To insert a MongoDB document we get the DBCollection, then create BasicDBObjects which we insert into the DBCollection. To nest a documnet we create a BasicDBList and insert BasicDBObjects into it. Then we add the BasicDBList to the parent BasicDBObject. The following snippit illustrates that sequence. It's mostly boilerplate code, with the only human decision being the nesting structure.
1: DBCollection filmCollection = mongoDb.getCollection(mongoCollection);
2:
3: while (fileRs.next()) { // For each film
4:
5: // Create the actors document
6: BasicDBObject filmDoc = new BasicDBObject();
7: Integer filmId = fileRs.getInt("FILM_ID");
8: filmDoc.put("_id", filmId);
9: filmDoc.put("Title", fileRs.getString("TITLE"));
10: // Other attributes
11: BasicDBList actorList = getActors(mysqlConn, filmId);
12: // put the actor list into the film document
13: filmDoc.put("Actors", actorList);
14: filmCollection.insert(filmDoc); // insert the film
15:
16: }
Anyway, hopefully this might be of some use to those moving from MySQL to MongoDB. Comments welcome!
