I was recently asked to provide advice on how best to accelerate Oracle database performance with flash SSD. In this post I’ll attempt to outline some thoughts on that.
There’s some thinking that SSD will soon replace spinning disk altogether - we just have to wait for the price to come down. However, I’m not so sure that this complete replacement is likely to occur in the immediate future. There are two competing forces at work:
- The economies of “big data”, which drive us to reduce the cost per unit of storage ($$/TB): magnetic disk costs only about 5% of the cost of a high end SSD per terabyte.
- The economies of high IO throughput, in which we are motivated to reduce the cost of providing a given IO rate. SSD (PCi flash) can generate IO rates at 1/20th of the cost of magnetic disks.
These two competing economies are not likely to change in the immediate future: magnetic disk can store large amounts of data much more cheaply than SSD; SSD can deliver very high IO rates more cheaply than magnetic disk. For most databases, it will not be cost effective to place the entire database on SSD – the best outcome will be obtained when we place parts of the database on SSD and some on magnetic disk.
SSD Performance basics
I’ve posted in the past on how SSD works with the Oracle flash cache, and I’ve presented on SSD performance at OOW. You might like to review those items. However, here’s a quick review of the basics:
- All flash drives offer pretty good read performance – say 25 microseconds for a single page read
- When inserting data into an empty page, performance is slower, but not awful – around 250 microseconds
- In order to update an existing page, a block erase is required – much, much slower – maybe 2000 microseconds

Enterprise SSD vendors - Fusion IO, Virident, etc - all have sophisticated algorithms to avoid the write penalty associated with SSD block erase operations. Amongst other techniques, they will maintain a pool of unused blocks. When a page needs to be updated it will be marked as invalid in the original location and moved to one of these blocks. Later on, garbage collection routines will clear up the invalid entries. The result is that updates don't always have to incur the high overhead of block erase operations.
Nevertheless, you want to avoid placing write intensive files on a flash disk, because as the disk fills up with modified blocks - and especially if the write rate exceeds the garbage collection capabilities - you might see the disk slow down dramatically.
To summarize:
Flash-based disks perform reads much faster than writes, and can suffer from performance degradation if subjected to intensive sustained write operations.
Options for SSD deployment on Oracle
Given the performance characteristics of SSD, how best to use SSD to boost Oracle performance? There are a few options:
- Put the entire database on SSD
- Place selected segments on SSD
- Use the 11GR2 flash cache
- Put temporary tablespace on SSD
- Put the redo logs on SSD
Let’s look at each of these in turn:
Put the entire Database on SSD
This works great – if you can afford it. For most databases the cost of putting it all on SSD is too high. Placing data that is rarely accessed on SSD is not very cost effective, because you are paying a high cost per GB, but not getting any benefit from the relatively cheap IO rates.
Place selected segments on SSD
This is probably the best option if you don’t have enough SSD for the entire database, but it does require a bit of configuration. We identify the segments with the most IO, perhaps using a query on V$SEGMENT_STATISTICS:

We are looking for object that have a high read/write ratio, contribute to a significant number of reads, and are small enough to fit on our SSD. We create a tablespace on SSD, then move these objects to that tablespace.
If our most read intensive tables are massive, then they might not fit on the SSD. In this case we could consider partitioning them and placing the hottest partitions on SSD.
Use the 11GR2 flash cache
If you have 11GR2 and are on a compatible platform (Solaris or Oracle Enterprise Linux), then you can setup the Oracle DB flash cache. This is absolutely the easiest option – all you need to do is set a few parameters and bounce the database. The flash cache automatically caches the hottest blocks and usually provides an excellent performance improvement.
The improvement is not as significant as moving objects directly onto flash storage, since there still has to be magnetic disk IO getting things on and off. Also, the architecture tends to create a lot of writes to the SSD, which can challenge garbage collection. The chart below sums up a typical outcome – a huge boost from the flash cache, but not as big a boost as we could get by putting objects directly on SSD:

Put temporary tablespace on SSD
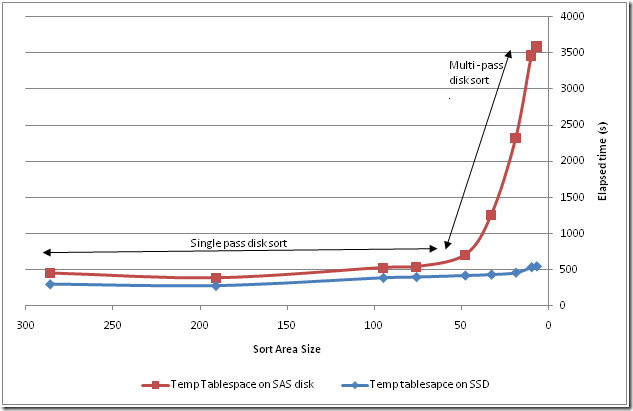
Temporary tablespace IO (from sorts and hash operations) can sometimes be the most significant form of database IO, and often the entire temporary tablespace will fit on the SSD. So should we consider putting temporary tablespace on the SSD?
I’m a bit reluctant to do this: by definition temporary tablespace IO is equal parts reads and writes, and since we are motivated to avoid write IO to the SSD, this seems like a dubious option. However, if your performance is absolutely dominated by temp tablespace IO and your SSD is tolerant of high write rates (eg has excellent garbage collection,etc) then it might be worth trying. After all, the SSD will definitely speed up the read side of temporary tablespace IO, even if the write IO does not get a significant boost.
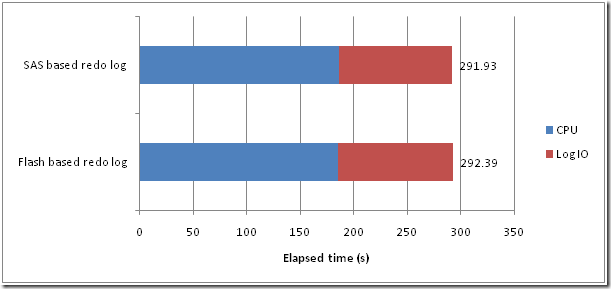
Put redo logs on SSD
Although redo logs are very IO intensive, it’s almost all write IO and therefore this is probably not the best option. During sustained writes the Garbage Collection will probably break down and the disk might not end up performing that much better than a spinning disk. I'd not recommend this.
Conclusions
You can use SSD to boost database performance even if you don’t have enough for the entire database. Best options are:
- Place segments with high read but low write rates directly on SSD
- Use the SSD with the 11GR2 database flash cache (if you are on OEL or Solaris)
- If temporary segment IO is absolutely your bottleneck – but only then – consider placing the temporary tablespace on SSD.
I don’t think using SSD for redo logs is a good idea. The high rates of sustained sequential write IO is not the ideal type of IO for SSD.